

The adequate representation and processing of target language by using the character set or character encoding is also a prerequisite for the localization of the linguistic elements of a product. This should not be a problem given the currently widespread use of UNICODE-Normen kein Problem sein. UNICODE represents a uniform and unique basis for the treatment of character sets of (nearly) all languages of the world. Therefore, it is common to use UNICODE standards for developing software products.
Before UNICODE and after the introduction of Windows operating systems into the market and their localised versions for the Asian markets, several different code pages (character encoding tables) were created to make available different character sets for Asian languages. The solution was not completely successful and became particularly problematic when Western and Asian character sets were used together in the same text (cf. Schmitz, 2005a:11)
The graphic below illustrates the problem when having different character sets together in a same source and support for all of them is missing. Since in our example the Western codepage (for Latin-based languages) is being used, German characters are shown correctly in the dialog box. But Japanese and Greek characters sets, which are not supported by the Western codepage, cannot be interpreted correctly and the computer shows them as question marks (cf. Sachse, 2005:151).
In the following graphic you can clearly see that the missing information needed for decoding the Japanese and Greek character sets is offered by UNICODE. In our example, UNICODE supports the three different types of character sets that appear together in our dialog message above.
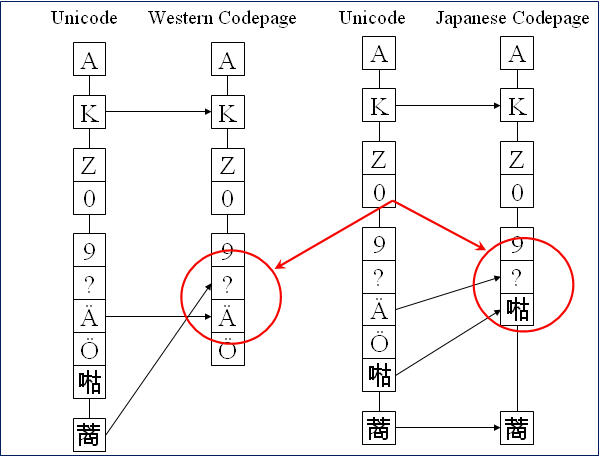
Missing information offered by UNICODE