
Some of the basic features of Translation Memory tools are:



These are rules for subdividing texts into smaller units (segments), on the basis of so-called 'sentence delimiters' (see Figure below). A segment can be defined as "a predefined unit of a text that can be aligned with its corresponding translation. Typically, the basic unit of segmentation is a sentence, but other units can also be defined as segments, such as headings, items in a list, cells in a table, or paragraphs." (Bowker 2002, 152)
In the Options box below, the content menu that appears when left-clicking, shows several options of possible sentence delimiters (digits, letters, any characters, white spaces, caret symbol, etc.) that translators can use to create their own segmentation rules and also their own exception rules, depending on the type of text or language of the text they are translating.


©eCoLoTrain
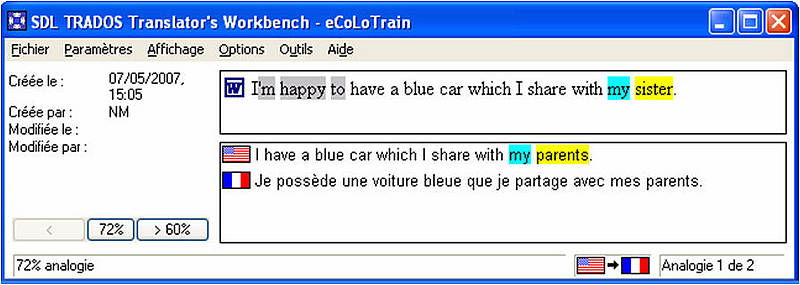
These are algorithms (computer programs) for looking up segments in the TM to find either exactly identical segments ("exact matches") or similar segments ("fuzzy matches").
Normaly, a fuzzy match with a degree of similarity bellow 75% is considered by the Translation Memory as a new segment. This setting can be of course changed, but most of the time it is recommended that the minimum match value is no lower than 75%, because the lower the fuzzy match is, the more translating will be required later. Actually, you can spend more time trying to adapt a fuzzy match with 75% of degree of similarity than translating from scratch.
Nevertheless, for situations where only small translation memories are available, the number of fuzzy matches is drastically reduced when setting a 75% threshold. The threshold can be reduced to up to 30% to benefit from such small databases. Such cases may occur during translation classes where students are starting with relatively small or empty translation memories.

A terminology database enables the translator to enter new terms or search for existing terms. The search is done using lookup algorithms which search for the terms contained in the source segment and can find "exact" as well as "fuzzy" matches.
Thus, even if there is no translation available in the TM for the whole source segment, terms contained in the source segment which do have a translation in the terminology database are found and displayed in a separate window. They can then be easily inserted into the target language segment.

These features can be used at the beginning of a translation project to calculate statistical data, like the word count of the text to be translated and the number of exact and fuzzy matches contained in the TM selected for the project. In order to make use of these features, the TM to be used for the project must either be specified in a project definition (e.g. in the case of Déjà Vu X) or be opened in the TM tool (e.g in Trados), before the number of matches can be calculated.

This component can be used for creating TMs from previous translation projects, where source texts and their translations are available. The alignment component tries to automatically match source and target segments and bind them together as translation units which can be added to an existing TM or used to create a new TM. This automatic process can be improved by manual input.
Nevertheless, bear in mind that alignment is a productivity tool, hence minimum efforts should be put into it. Moreover, when deciding what documents to align, think about their relevance to your future work.