
Algunas de las funciones básicas de las herramientas de las Memorias de Traducción son:

©eCoLoTrain

©eCoLoTrain

©eCoLoTrain
Reglas de segmentación son reglas para subdividir textos en unidades más pequeñas (segmentos), basándose en los así llamados 'delimitadores de oraciones' (ver el gráfico de abajo). Se puede definir a un segmento como «una unidad pre-establecida de un texto que puede ser alineada con su traducción correspondiente. Normalmente, la unidad básica para la segmentación es una oración, pero también se pueden establecer otras unidades como segmentos, como títulos, elementos de una lista, celdas de una tabla, párrafos.» (Bowker 2002, 152)
En el cuadro Opciones de abajo, el contenido del menú que aparece cuando de hace clic con el botón izquierdo del ratón, muestra varias opciones de posibles delimitadores (dígitos, letras, cualquier tipo caracteres, espacios en blanco, el símbolo de caret, etc.) que el traductor puede utilizar para establecer sus propias reglas de segmentación y reglas de excepción, dependiendo del tipo de texto o idioma del texto que se traduce.
©eCoLoTrain

©eCoLoTrain

©eCoLoTrain
©eCoLoTrain
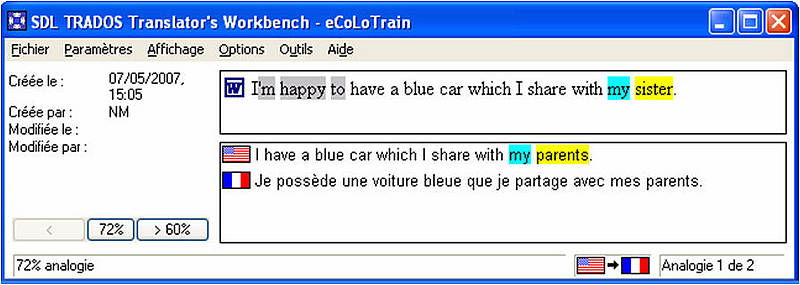
Estos algorítmos (programas informáticos) para buscar segmentos en la MT encuentran segmentos completamente idénticos («exact matches») o segmentos similares («fuzzy matches»).
Por lo general, la Memoria de Traducción considera a un «fuzzy match» con un grado de similitud menor al 75% como un segmento nuevo. Esta configuración se puede cambiar, pero la mayoría de las veces se recomienda que el valor mínimo de la coincidencia no sea menor al 75%, porque mientras menor sea la conicidencia, más tiempo se necesitará después para la traducción. En realidad, podría pasar más tiempo tratando de adaptar una coincidencia parcial con un grado de similitud de 75% que traduciendo todo el segmento desde cero.
Sin embargo, si sólo se dispone de memorias de traducción pequeñas, el número de coincidencias parciales se reduce de manera drástica cuando se pone un límite de 75%. Se puede reducir el límite hasta el 30% para poder beneficiarse de bases de datos pequeñas. Esto último puede ocurrir durante las clases de traducción, dónde los estudiantes empiezan a trabajar con memorias de traducción relativamente pequeñas o vacías.

©eCoLoTrain
Una base de datos de terminología permite al traductor ingresar nuevos términos o buscar existentes. La busqueda se hace usando algorítmos de búsqueda que se encargan de buscar los términos que se encuentran en el segmento original y que pueden encontrar concidencias exactas y parciales (fuzzy matches).
Por lo tanto, incluso si no se dispone de una traducción en la MT para todo el segmento original, los términos del segmento original que sí tienen una traducción en la base de datos de terminología son buscados y se muestran en una página aparte. Se los puede ingresar fácilmente al segmento del idioma de destino.

©eCoLoTrain
Estas funciones pueden ser utilizadas al comenzar un proyecto de traducción para calcular datos estadísticos como contar las palabras del texto a traducir y el número de coincidencias exactas y parciales en la MT seleccionada para el proyecto. Para poder usar estas funciones, la MT que se ha de usar para el proyecto debe ser especificada en el proyecto (p.ej. en el caso de Déjà Vu X) o debe ser abierta en una herramienta de MT (p.ej. en Trados) antes de calcular el número de coincidencias.

©eCoLoTrain
Este componente puede ser usado para crear MT desde proyectos de traducción previos, donde están disponibles los textos originales y sus traducciones. El componente de alineamiento trata de encontrar automáticamente segmentos de origen y de destino que coinciden y unirlos como unidades de traducción que pueden ser agregadas a una MT o usadas para crear una nueva MT.
Se pueden hacer mejoras a este proceso manualmente. Sin embargo, tenga presente que el alineamiento es una herramienta de productividad y, por lo tanto, se le debe poner sólo un esfuerzo mínimo. Además, al decidir qué documentos alinear, debe pensar en su importancia para trabajos posteriores.