
Grundlegende Eigenschaften von TM-Tools (2/10)
Einige grundlegende Eigenschaften von Translation Memory-Tools sind:

©eCoLoTrain

©eCoLoTrain

©eCoLoTrain
Segmentierungsregeln sind Regeln für die Unterteilung von Texten in kleinere Einheiten (Segmente) durch sogenannte Segmentbegrenzer ("Sentence delimiters") (siehe Screenshot). Ein Segment kann definiert werden als "eine vordefinierte Texteinheit, die mit der dazugehörigen Übersetzung aligniert werden kann. Typischerweise ist die Grundeinheit einer Segmentierung ein Satz, jedoch können auch andere Einheiten als Segmente definiert werden wie Überschriften, Listeninhalte, Zellen einer Tabelle oder Abschnitte." (Bowker 2002, 152)
Im Dialogfeld Optionen, zeigt das Menü, das beim Linksklick erscheint, verschiedene Möglichkeiten für Segmentbegrenzer (Ziffern, Buchstaben, alle möglichen Zeichen, Leerzeichen, Zirkumflexe etc.), die Übersetzer verwenden können, um ihre eigenen Segmentierungsregeln und auch ihre eigenen Ausnahmefälle zu schaffen, und zwar abhängig von Textsorte oder Ausgangssprache.
©eCoLoTrain

©eCoLoTrain

©eCoLoTrain
©eCoLoTrain
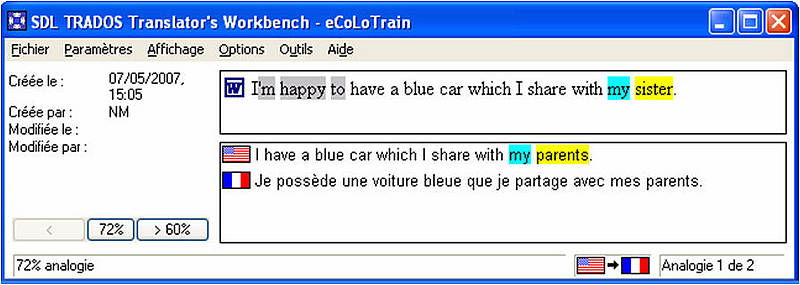
Es handelt sich hierbei um Algorithmen (Computerprogramme), die Segmente im TM nachschlagen, um entweder identische Segmente ("exakte Treffer") oder ähnliche Treffer ("Fuzzy Matches") zu finden.
Normalerweise wird ein Fuzzy Match mit einem Übereinstimmungsgrad unter 75% von dem Translation Memory als neues Segment eingestuft. Diese Einstellung kann man natürlich ändern, jedoch wird empfohlen, dass die kleinstmögliche Übereinstimmung 75% betragen sollte, da bei einem niedrigeren Wert im Nachhinein ein höherer Übersetzungsaufwand notwendig ist. Tatsächlich kann es mehr Zeit in Anspruch nehmen, einen 75%-igen Fuzzy Match anzugleichen, als das Segment neu zu übersetzen.
Wenn jedoch nur ein kleines Translation Memory zur Verfügung steht, würde bei einem Schwellenwert von 75% die Anzahl an Fuzzy Matches drastisch reduziert. In solchen Fällen kann man den Wert auf bis zu 30% senken, um von solchen kleinen Datenbanken zu profitieren. Dies kann zum Beispiel im Übersetzungsunterricht der Fall sein, bei dem Studierende mit relativ kleinen oder leeren Translation Memories beginnen.

©eCoLoTrain
Eine Terminologiedatenbank ermöglicht es dem Übersetzer, neue Begriffe einzugeben oder bereits erfasste Begriffe zu suchen. Die Suche erfolgt durch die Verwendung von Such-Algorithmen, welche die Begriffe innerhalb des Ausgangssegments suchen und sowohl "genaue" als auch "fuzzy" Matches finden können.
So können Begriffe, zu denen es bereits eine Übersetzung in der Terminologiedatenbank gibt, gefunden und in einem separaten Fenster angezeigt werden, auch wenn es noch keine passende Übersetzung für das vollständige Ausgangssegment im TM gibt. Diese können ganz einfach in das Zielsprachensegment eingefügt werden.

©eCoLoTrain
Analyse und Statistik können zu Beginn eines Übersetzungsprojekts verwendet werden, um statistische Daten zu erfassen wie die Wortanzahl des zu übersetzenden Texts und die Anzahl der genauen Treffer und Fuzzy Matches, die das für das Projekt ausgewählte TM beinhaltet. Um diese Funktionen einsetzen zu können, muss das für das Projekt zu verwendende TM entweder in der Projekt-Definition spezifiziert (z.B. im Fall von Déjà Vu X) oder in einem TM-Tool (z.B. in Trados) geöffnet werden, bevor die Anzahl der Matches berechnet werden kann.

©eCoLoTrain
Diese Komponente wird verwendet, um TMs aus früheren Übersetzungsprojekten zu erstellen, von denen es Ausgangstexte und dazugehörige Übersetzungen gibt. Die Alignment-Komponente versucht, Entsprechungen zwischen Ausgangs- und Zielsegmenten zu finden und sie zu Übersetzungseinheiten zu verbinden, die von bestehenden TMs oder bei der Schaffung von neuen TMs verwendet werden können.
Dieser automatische Prozess kann manuell verbessert werden. Vergessen Sie trotzdem nicht, dass es sich bei Alignment um ein Produktivitätstool handelt und somit möglichst wenig Aufwand erfordern sollte. Außerdem sollte man vor dem Alignment von Dokumenten darüber nachdenken, inwiefern sie für die künftige Arbeit relevant sein können.