
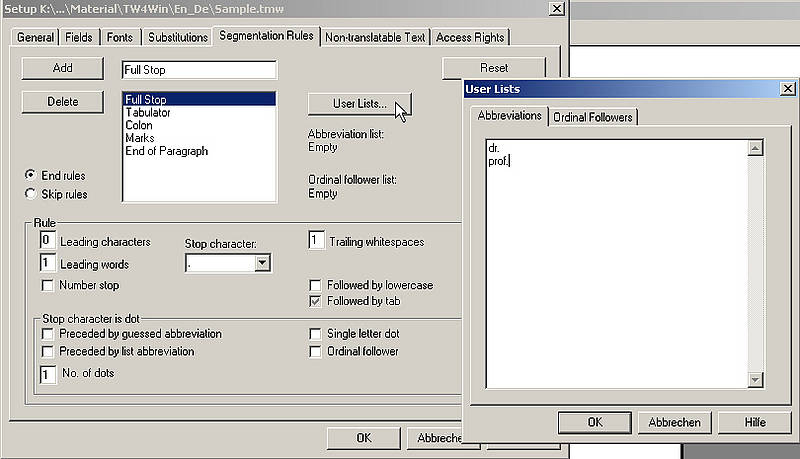
For the analysis module to successfully calculate matches between segments, the segments in a text must first be identified. This is done by segmenting the text either during the analysis process or during the import process.
Segmentation of texts is mainly based on punctuation: full stops, colon, question and exclamation marks, tabs, and paragraph marks are by default regarded as segment delimiters. In addition, the user can specify exceptions to these segmentation rules, for example, abbreviations which are followed by a full stop, but never or seldom occur at the end of a sentence.