
Translation Memories 3
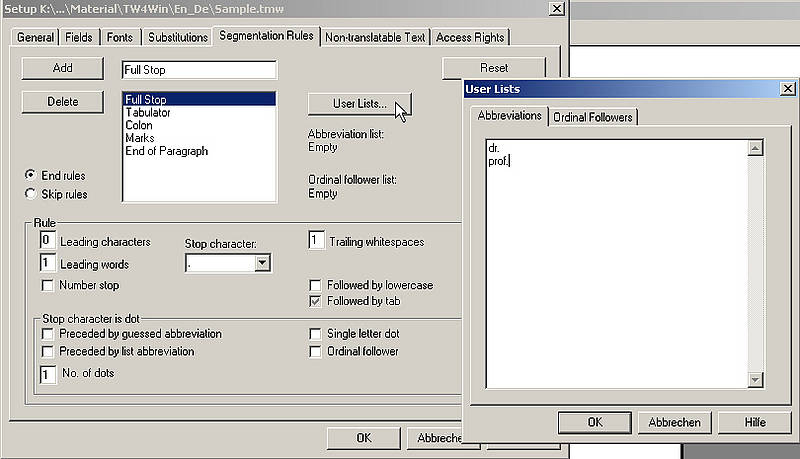
Segmentierungsregeln (3/8)
©eCoLoTrain
Um erfolgreich Treffer zwischen Segmenten errechnen zu können, müssen die Segmente in einem Text zunächst identifiziert werden. Dies erreicht man durch Segmentierung des Texts während der Analyse oder während des Imports.
Die Segmentierung eines Texts basiert hauptsächlich auf Satzzeichen: Punkte, Doppelpunkte, Frage- und Ausrufezeichen, Tabstopps und Absätze werden als Segmentgrenzen ('Segment Delimiters') angesehen. Außerdem kann der Benutzer Ausnahmen zu diesen Segmentierungsregeln definieren, z. B. von einem Punkt gefolgte Abkürzungen, die selten oder nie an einem Satzende vorkommen.