
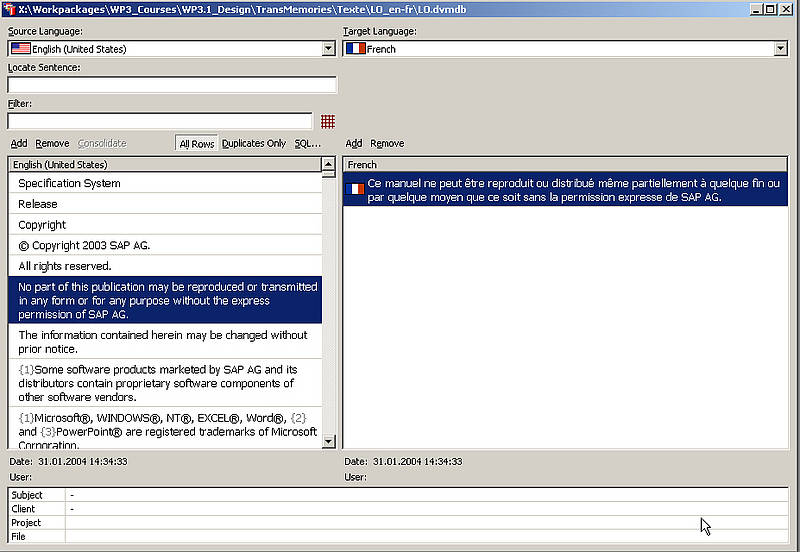
The core component of a TM system is the Translation Memory itself. In most TM systems the Translation Memory is a database containing data fields with translation units (segments) in source and target language(s), plus additional information such as:
- date of creation of a translation
- date of last modification
- name of the user who created an entry
- information about the client for whom a translation has been made, or
- information about the translation project
These categories are pre-defined in some systems; in others the user can specify them. Some TMs offer the possibility of creating entries in an almost unlimited number of languages (restricted only by the number of languages of the computer's operating system). In such TMs the language pair used by the translator is specified at the beginning of a translation project.
Other TM systems have a single, fixed source language and a user-definable number of target languages; in these systems the language direction cannot be inverted. If the translator wants to use the data of the TM in the opposite language direction, the data have to be exported from the TM database and imported into a different database defined for the inverted language direction. In just a few TM systems (e.g. STAR Transit), the TM consists of pairs of source and target language text files (text corpora, reference files) which are created by translating texts using the system .
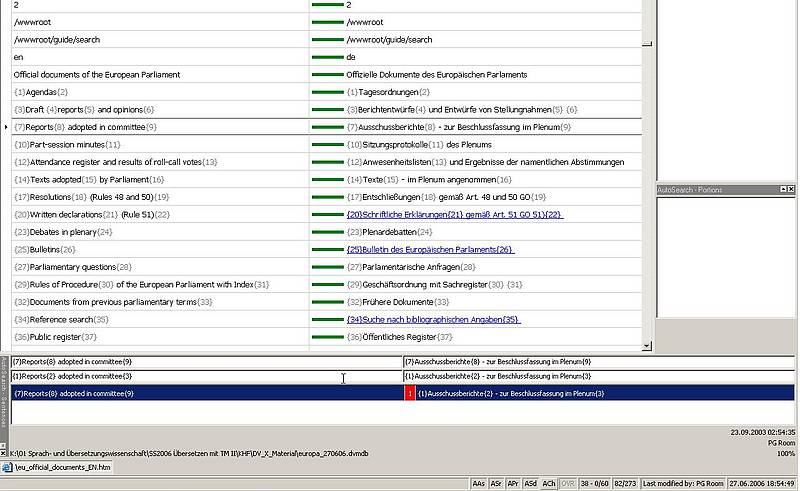
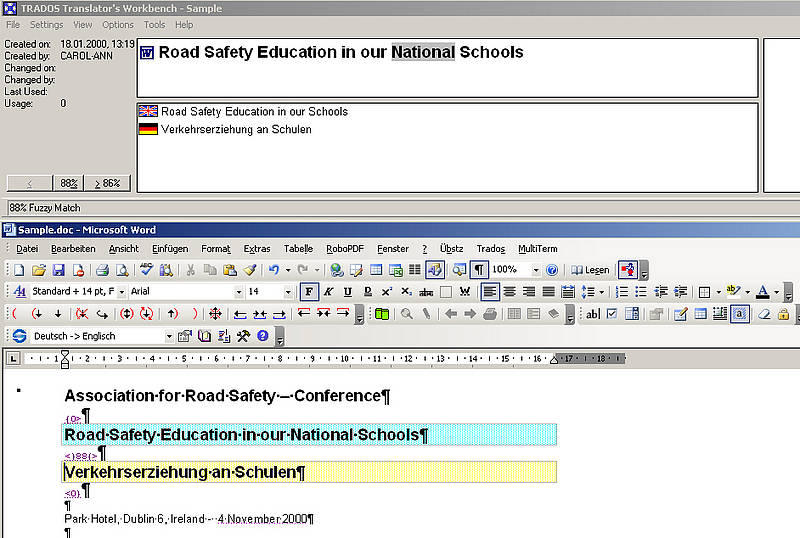
During translation, source language segments are looked up in the TM database. This can be done either automatically, when a segment is opened by placing the cursor in the segment, or manually sentence by sentence. If the TM contains an exactly matching source language segment, this segment is displayed in the TM part of the window together with its translation and the additional information stored with the segment in the database. The degree of similarity is displayed as 100%.
If the TM contains only a segment which is not identical but merely similar to the source segment, this segment is also displayed together with its translation and the degree of similarity calculated by the TM system. Such a non-exact segment is called a "fuzzy match" in all TM systems.
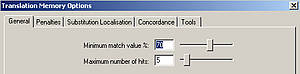
The threshold for the degree of similarity acceptable to the translator can be customised in all TM systems.
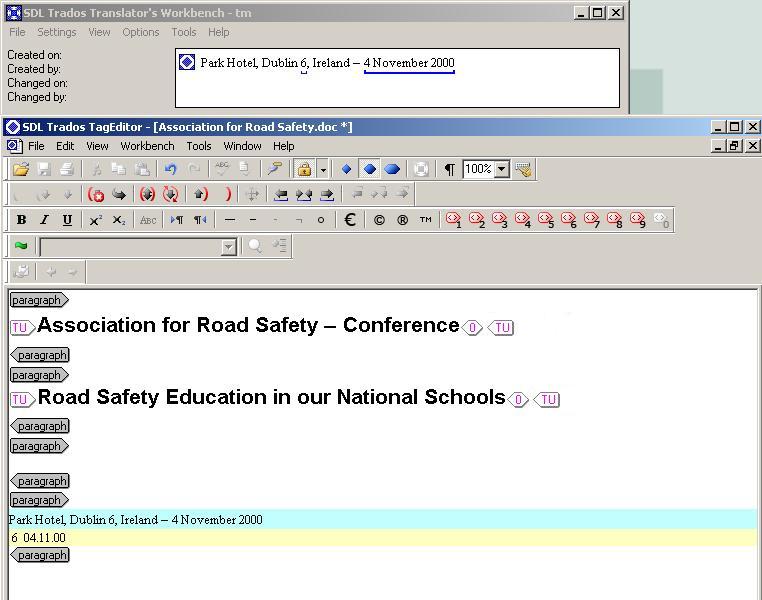
Some TM systems are able to recognise text elements such as numbers, dates and units of measurement. These elements, called "placeables", are then converted automatically into the standard format of the target language and can be copied to the correct location in the target language segment.
After a segment has been looked up, the translation can be accepted, modified or replaced by a new one. If neither exact nor fuzzy matches are found, a new translation has to be created and saved to the TM. Usually, the saving is done automatically by the TM system, when the current segment is closed. After this, the new translation unit is available, if the same or a similar segment occurs in the source language text again.
Besides adding new segments during the translation process, it is also possible to add new segments by importing the contents of other TMs. These may have been created using the same Translation Memory system by other translators, or created in different systems and then made available in an exchange format which can be read and processed by the receiving TM systems.