
Komponenten von TMs: Translation Memory (10/10)
©eCoLoTrain
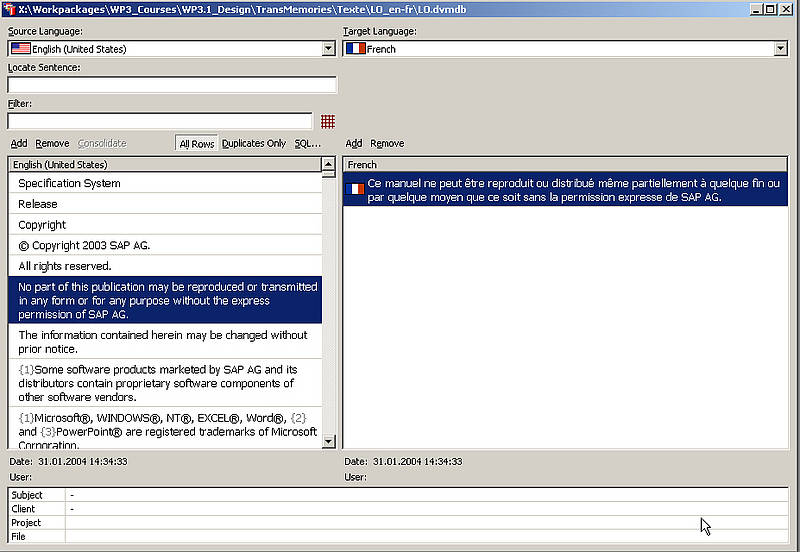
Das Herzstück eines TM-Systems ist das Translation Memory selbst. In den meisten TM-Systemen ist das Translation Memory eine Datenbank, die Datenfelder mit Übersetzungseinheiten (Segmenten) in Ausgangs- und Zielsprache(n) und zusätzliche Informationen beinhaltet, wie:
- Anfertigungsdatum einer Übersetzung
- Datum der letzten Bearbeitung
- Name des Benutzers, der einen Eintrag erstellt hat
- Informationen über den Kunden, für den eine Übersetzung angefertigt wurde oder
- Informationen über das Projekt der Übersetzung
In einigen Systemen sind diese Kategorien vordefiniert, in anderen kann der Benutzer sie spezifizieren. Einige TMs bieten die Möglichkeit, Einträge in einer fast uneingeschränkten Anzahl an Sprachen zu verfassen (Einschränkungen erfolgen höchstens von Seiten des Betriebssystems des Rechners). In solchen TMs wird das Sprachenpaar, das der Übersetzer benutzt, vor dem Beginn des Übersetzungsprojekts festgelegt.
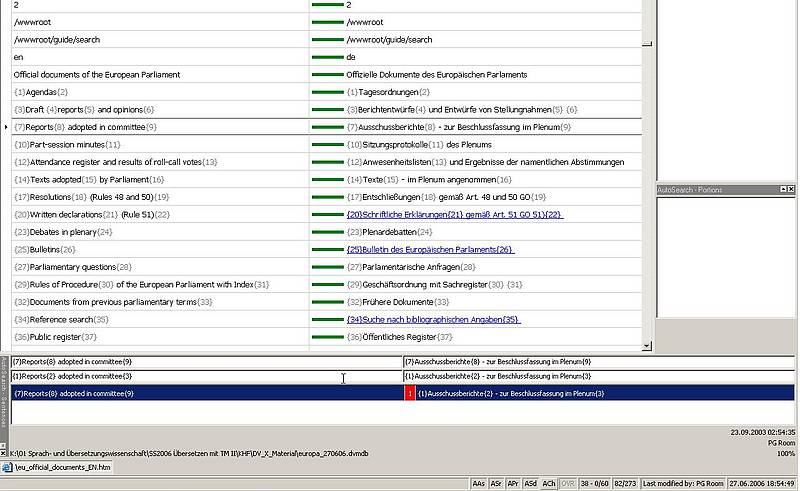
Bei anderen TM-Systemen gibt es eine einzige festgelegte Ausgangssprache und eine von dem Benutzer festzulegende Anzahl an Zielsprachen; bei diesen Systemen ist es nicht möglich, die Sprachrichtung umzukehren. Möchte der Übersetzer die Daten eines TM in die umgekehrte Richtung verwenden, müssen die Daten von der TM-Datenbank exportiert und in eine andere Datenbank importiert werden, die für die andere Sprachenrichtung definiert wurde. Bei nur wenigen TM-Systemen (z.B. STAR Transit) besteht das TM aus ausgangs- und zielsprachlichen Textpaaren (Korpora, Referenzdateien), die aus Übersetzungen stammen, welche vom TM-System angelegt wurden.
©eCoLoTrain
©eCoLoTrain
©eCoLoTrain
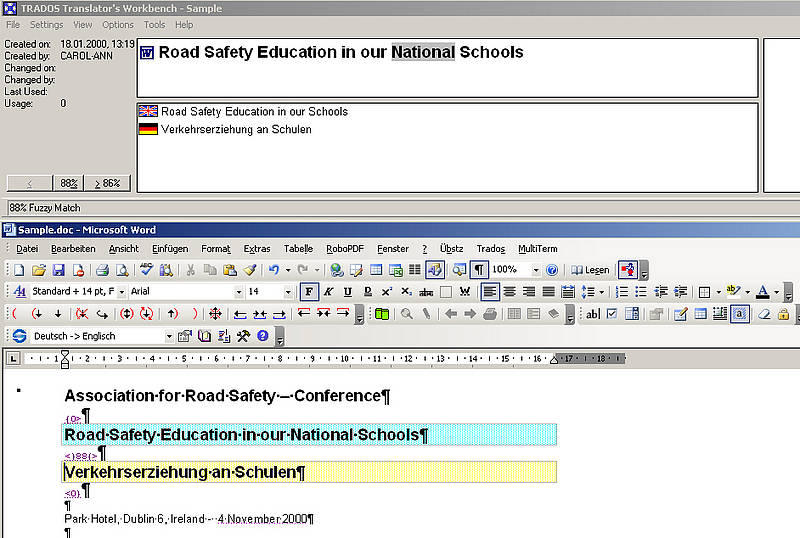
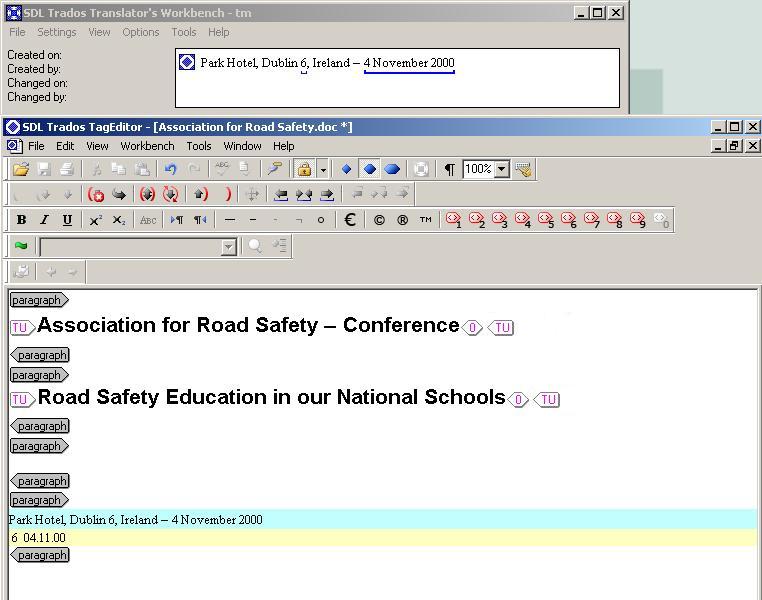
Während des Übersetzens werden ausgangssprachliche Segmente in der TM-Datenbank nachgeschlagen. Dies kann entweder automatisch erfolgen, wenn ein Segment geöffnet und der Cursor in dem Segment platziert wird, oder Satz für Satz von Hand. Wenn es in dem TM ein exaktes Ausgangssprachensegment gibt, wird dieses Segment mit seiner Übersetzung und der dazugehörigen gespeicherten Zusatzinformation in dem TM-Abschnitt des Fensters angezeigt. Der Grad der Übereinstimmung wird als 100% angezeigt.
Wenn es in dem TM lediglich ein Segment gibt, das zwar nicht identisch, jedoch dem Ausgangssegment sehr ähnlich ist, wird dieses Segment ebenfalls mit seiner Übersetzung und dem errechneten Übereinstimmunsgrad von dem TM-System angezeigt. Dieses nicht ganz exakte Segment wird in allen TM-Systemen als "Fuzzy Match" bezeichnet.
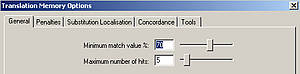
Der Schwellenwert für den akzeptablen Übereinstimmungsgrad für den Übersetzer kann in allen TM-Systemen angepasst werden.
©eCoLoTrain
Einige TM-Systeme sind in der Lage, Textelemente wie Nummern, Daten und Maßeinheiten zu erkennen.
Diese Elemente - auch 'Placeables' genannt - werden dann automatisch in das Standardformat der Zielsprache umgewandelt und können an die korrekte Stelle des Zielsprachensegments kopiert werden.
Nachdem ein Segment nachgeschlagen wurde, kann die Übersetzung akzeptiert, modifiziert oder durch eine neue ersetzt werden. Falls es kein exaktes oder Fuzzy-Match gibt, muss eine neue Übersetzung angefertigt und in das TM eingespeist werden. Im Normalfall erfolgt das Abspeichern automatisch durch das TM-System, wenn das Segment geschlossen wird. Danach ist die neue Übersetzungseinheit verfügbar, wenn ein gleiches oder ähnliches Segment im Ausgangstext auftritt.
Außer dem Hinzufügen von neuen Segmente während des Übersetzungsprozesses ist es auch möglich neue Segmente hinzuzufügen, indem Inhalte andere TMs importiert werden. Diese können von andern Übersetzern im gleichen TM-System oder in anderen Systemen erstellt worden sein und dann in einem Austausch-Format, das von den empfangenden TM-Systemen gelesen und verarbeitet werden kann, zur Verfügung gestellt werden.