
©eCoLoTrain
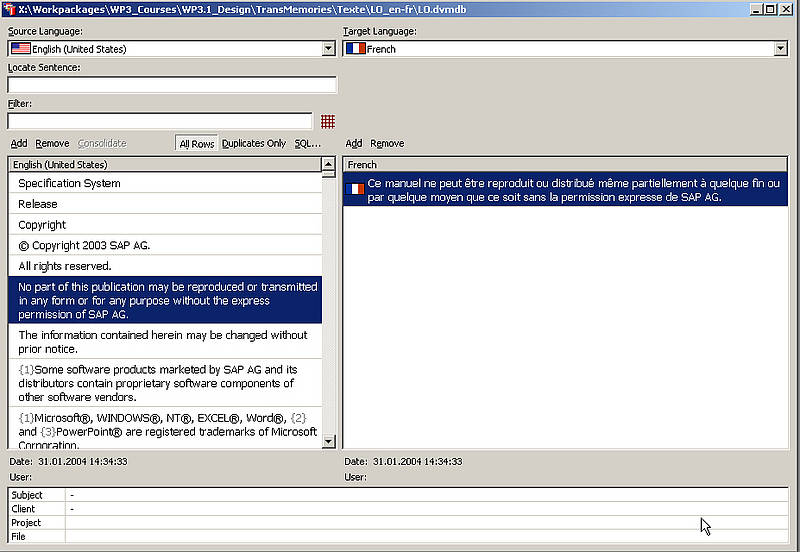
El componente central de un sistema de MT es la misma Memoria de Traducción. En la mayoría de los sistemas de MT, la Memoria de Traducción es una base de datos que contiene campos de datos con unidades de traducción (segmentos) en lo(s) idiomas(s) de origen y de destino, además de información adicional como:
- La fecha en la que fue hecha una traducción
- La fecha de la última modificación
- El nombre del usuario que ingresó un término
- La información sobre el cliente para el que fue hecha la traducción, o
- La información sobre el proyecto de traducción
En algunos sistemas estas categorías están pre-establecidas; en otros, será el usuario quien podrá establecerlas. Algunas MT ofrecen la posibilidad de ingresar términos en un número casi ilimitado de idiomas (restringido solo por el número de idiomas que posee el sistema operativo de un ordenador).
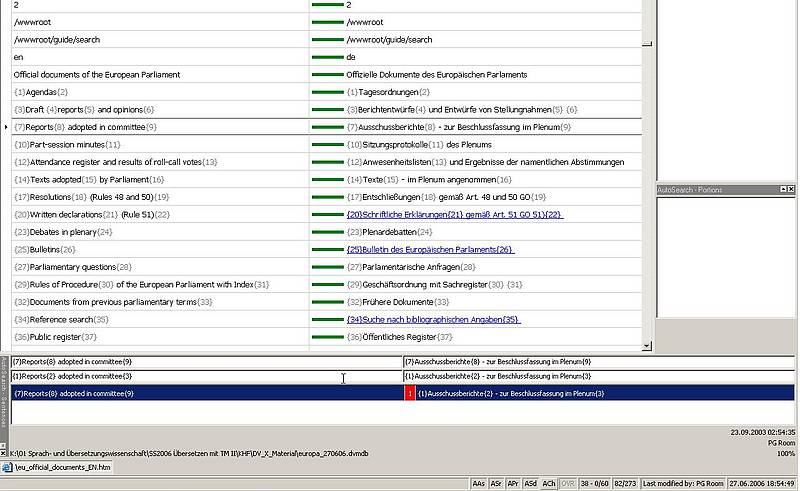
En tales MT, la pareja de idiomas usada por el traductor está especificada al comienzo de un proyecto de traducción. Otros sistemas de MT tienen sólo un idioma de origen fijo y un número de idiomas de destino que pueden ser establecidos por el usuario; en dichos sistemas la dirección no puede ser invertida. Si el traductor desea usar datos de la MT en la dirección de idiomas opuesta, los datos deben ser exportados desde la base de datos de MT e importados a una base de datos diferente establecida para la dirección inversa del idioma. Sólo en algunos sistemas de MT (p.ej. STAR Transit), la MT esta compuesta por pares de archivos de texto en el idioma de origen y de destino (corpus, archivos de referencia) que son creados al traducir textos usando el sistema.
©eCoLoTrain
©eCoLoTrain
©eCoLoTrain
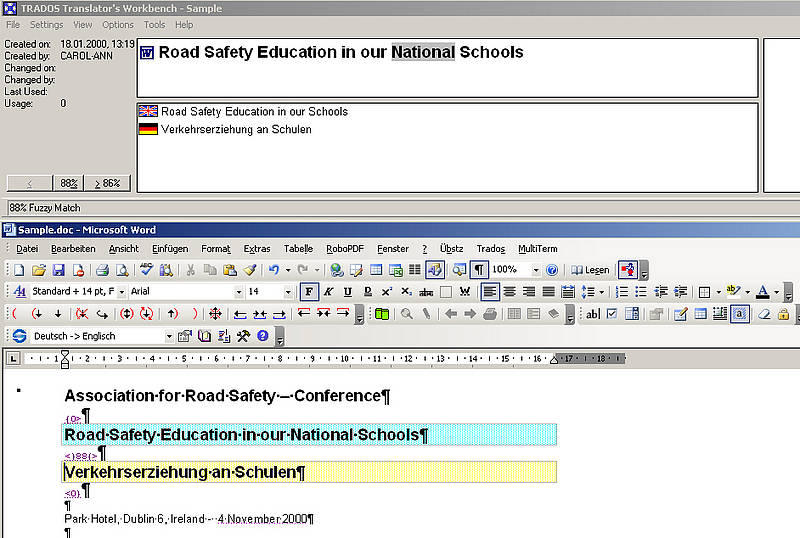
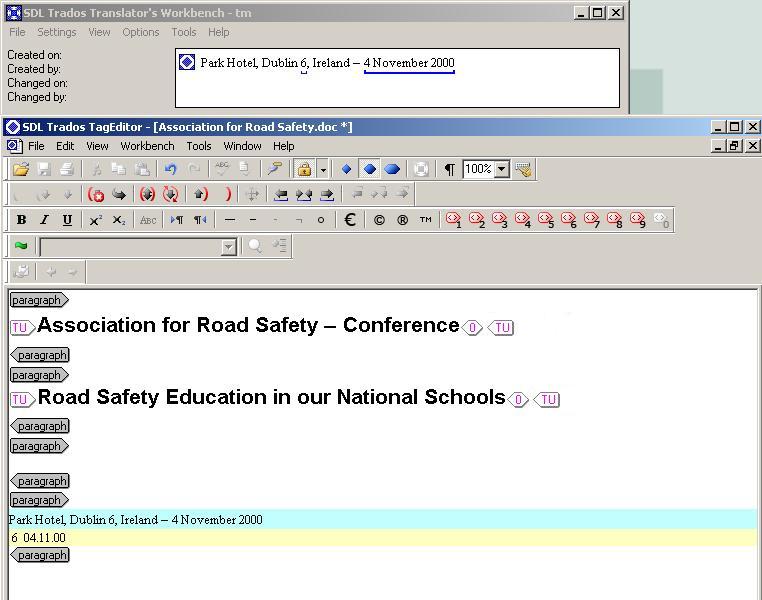
Durante la traducción, se buscan en la base de datos de la MT segmentos del idioma de origen. Esto puede hacerse automáticamente, cuando se abre un segmento poniendo el cursor en el segmento o manualmente oración por oración. Si la MT posee un segmento en el idioma de origen que coincide exactamente, este segmento se mostrará en la parte de MT de la ventana, junto con su traducción y la información adicional guaradada con el segmento en la base de datos. El grado de similitud es del 100%.
Si la MT contiene sólo un segmento que no es idéntico, sino simplemente similar al segmento de origen, este segmento también se mostrará junto con su traducción y el grado de similitud calculado por el sistema MT. Un segmento no exacto es llamado «fuzzy match» (coincidencia parcial) en todos los sistemas de MT.
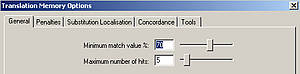
El límite del grado de similitud aceptable para el traductor se puede adaptar en todos los sistemas de MT.
©eCoLoTrain
Algunos sistemas de MT son capaces de reconocer elementos de texto como números, fechas y unidades de medida.
Estos elementos, llamados «placeables», son convertidos luego automáticamente al formato estándar del idioma de destino y pueden ser copiados en el lugar correcto en el segmento del idioma de destino.
Después de buscar un segmento, la traducción puede ser aceptada, modificada o reemplazada por una nueva. Si no se encuentran coincidencias parciales ni exactas, se tiene que crear una nueva traducción y guardarla en la MT. Por lo general, el sistema de MT guarda automáticamente la traducción cuando se cierra el segmento. Luego, la nueva unidad de traducción estará disponible en el caso que se vuelva a producir un segmento igual o similar en el texto del idioma de origen.
Además de agregar nuevos segmentos durante el proceso de traducción, también es posible agregar nuevos segmentos importándo el contenido de otras MT. Éste contenido puede haber sido creado por otros traductores usando el mismo sistema de Memoria de Traducción, o creado en sistemas diferentes y luego puestos a disposición en un formato de intercambio que puede ser leído y procesado por los sistemas de MT receptores.