
© eCoLoTrain
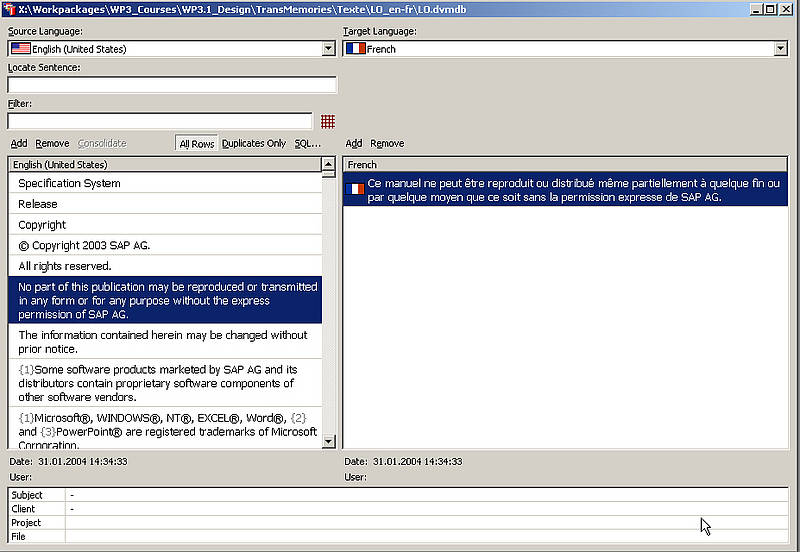
L'élément central d'un système de MT est la mémoire de traduction en elle-même. Dans la plupart des systèmes de MT, la mémoire de traduction est une base de données qui comporte des champs de données avec des unités de traduction (segments) en langue(s) source(s) et cible(s) ainsi que des informations complémentaires telles que :
- la date de création d'une traduction
- la date de la dernière modification
- le nom de l'utilisateur ayant créé une entrée
- les informations sur le client pour qui la traduction a été réalisée ou
- les informations sur le projet de traduction
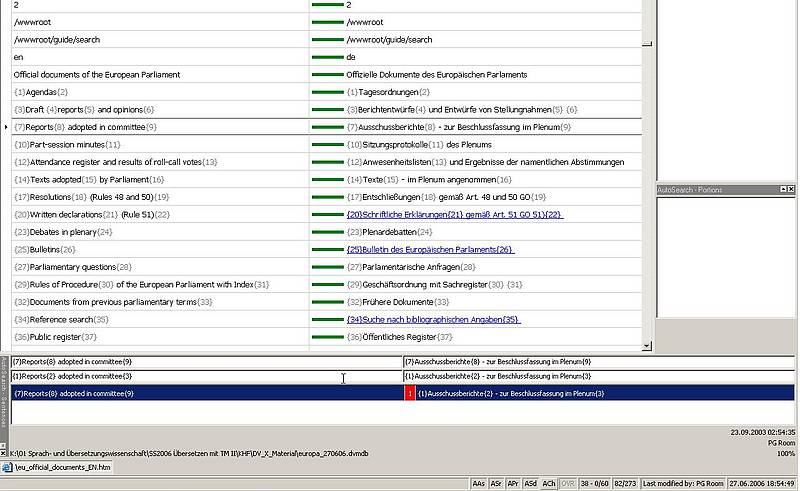
Ces catégories sont prédéfinies dans certains systèmes. Dans d'autres, l'utilisateur doit les définir. Certaines MT permettent de créer des entrées dans un nombre quasi illimité de langues (nombre restreint uniquement par le nombre de langues que comporte le système d'exploitation de l'ordinateur). Dans de telles MT, la paire de langue que le traducteur souhaite utiliser doit être indiquée au début du projet de traduction.
D'autres systèmes de MT ne proposent qu'une seule langue source et un nombre de langues cibles définissable par l'utilisateur. Dans ces systèmes, le sens de la traduction ne peut pas être inversé. Si le traducteur souhaite utiliser les données de la MT dans l'autre sens de traduction, les données doivent être exportées de la base de données de la MT et importées dans une autre base de données ayant été définie pour ce sens de traduction. Seuls quelques systèmes de MT (par exemple STAR Transit) ont une MT composée de paires de fichiers texte en langue source et cible (corpus de textes, fichiers de référence) qui sont créées lors de la traduction de textes à l'aide du système.
© eCoLoTrain
© eCoLoTrain
© eCoLoTrain
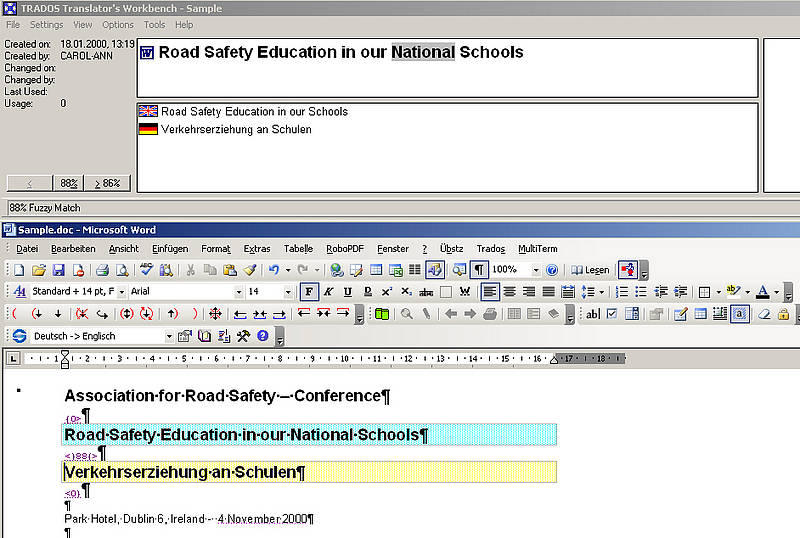
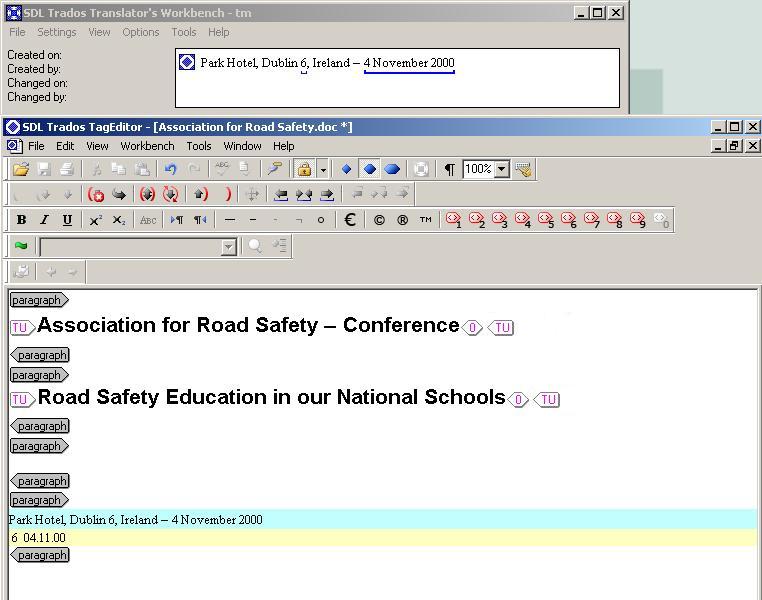
Au cours de la traduction, les segments en langue source sont recherchés dans la base de données de la MT. Cette recherche s'effectue soit automatiquement en plaçant le curseur dans le segment ouvert, soit manuellement, c'est-à-dire phrase par phrase. Si la MT contient un segment source ayant une analogie parfaite, ce segment est affiché dans la fenêtre de la partie MT avec sa traduction et les informations complémentaire enregistrées avec le segment dans la base de données. Le taux de similarité est de 100 %.
Si la MT contient seulement un segment qui n'est pas identique mais juste similaire au segment source, ce segment est également affiché avec sa traduction et le taux de similarité est établi par le système de MT. Ces segments dont l'analogie n'est pas parfaite sont appelés "analogies partielles" dans tous les systèmes de MT.
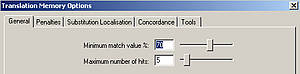
La valeur minimale du taux de similarité peut être personnalisée dans tous les systèmes de MT.
© eCoLoTrain
Certains systèmes de MT sont capables de reconnaître des éléments du texte tels que les nombres, les dates et les unités de mesure. Ces éléments sont des "éléments transposables". Ils sont automatiquement convertis dans le format standard de la langue cible et peuvent être insérés à l'emplacement correspondant dans le segment cible.
Après qu'un segment a été recherché, la traduction peut être acceptée, modifiée ou remplacée. Si aucune analogie parfaite ou partielle n'a été trouvée, une nouvelle traduction doit être créée et sauvegardée dans la MT. En général, la sauvegarde est effectuée automatiquement par le système de MT lorsque le traducteur ferme le segment. Ensuite, la nouvelle traduction est réutilisable si un segment identique ou similaire apparaît à nouveau dans le texte source.
Les outils de MT permettent d'ajouter de nouveaux segments à la MT pendant le processus de traduction mais également d'ajouter de nouveaux segments en important le contenu d'autres MT. Celles-ci peuvent avoir été créées à l'aide du même système de mémoire de traduction ou par d'autres traducteurs. Elle peuvent également avoir été créées dans différents systèmes et converties dans un format d'échange pouvant être lu et traité par le système de MT dans lequel elles vont être importées.