
If no TM is available for the translation to be done, you have to create one. There are two strategies for creating a TM: while translating (the more common procedure), or by aligning previous translations. In both cases you create an empty TM, which you can populate whilst translating your text – first scenario – or by using the results of an alignment previously carried out.
A TM can also be created during the process of creating a translation project (see our course Translating with a TM) or at any time before starting the translation proper. In this last case, the TM will be created as a stand-alone file which can later be associated with different project files.
Usually, the first translation performed using a TM system is started with an empty Translation Memory. In the present course we will go through the creation of a stand-alone TM.
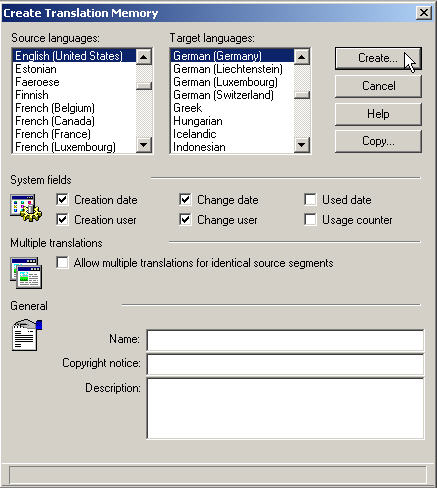
One of the first steps when creating a translation memory consists in selecting the languages of the data that you are going to store in your TM. A TM includes at least two languages: the source language (SL) and the target language (TL). The majority of TM applications support all languages and almost all of them even allow you to specify regional varieties of a language.
When selecting the languages of your TM it is important to make sure that you use them consistently, because a wrong selection of the language or language variety can trigger problems later on.
However, there are applications where the language settings are predefined and include all languages. Therefore it is unnecessary to define the languages when using these applications (e.g. Déjà Vu).
The graphic shows the selection of languages when creating a TM in Trados.

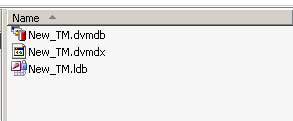
Another basic step when creating TMs is file management. A TM can consist of one file - for example .txt file in Wordfast - or several files in different formats – e.g. in Déjà Vu X: *.dvmdb, *.dvmdx (these two files are always created) and as many *.XX.dvmdi files as there are languages in the TM, where XX is the 2-letter ISO code of a particular language. That is why it is important to define the folder structure or working environment before creating the TM.
When creating a stand-alone TM, its location will generally be defined at the beginning of the creation process.
The empty TM file is then created. The graphic on the right shows an example of a TM file "New_TM.dvmdb" for the application Déjà Vu X – *.mdb is the extension for the translation memory database.

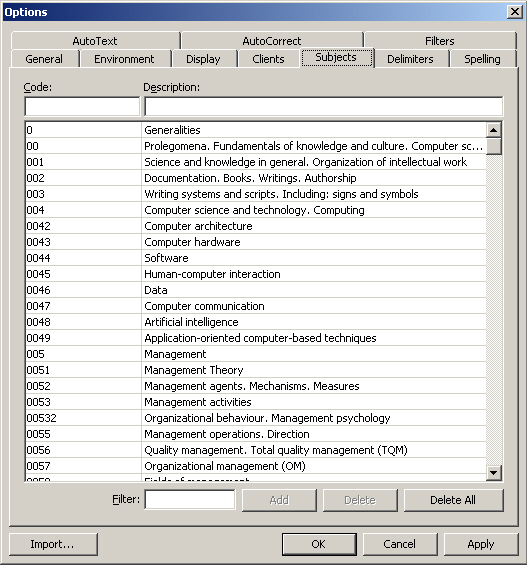
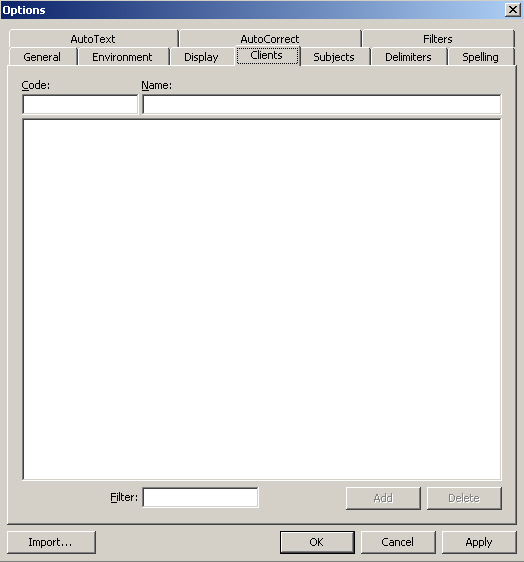
Depending on the TM application, there are several user definition options that can be set when creating a TM. User definitions usually refer to the additional information about the database itself or about the translation units that is stored with the source and target segments in the database. This extra information can also be used as a criterion for extracting information from the database (a criterion for filters).
It is worth noting that in some TM applications the information fields for the user definitions are predefined, but can be modified according to the user's needs when a translation project is created (e.g. Déjà Vu). In other TM applications, all information fields for the user definitions must be created and defined when creating the translation database (e.g. Trados).
Examples
User: name or nickname of the user who entered a specific record in the translation memory
Date/time of creation: the date and time the record was entered into the database
Subject: the subject or specialisation area of the texts contained in the database
Client: the user-assigned client of a record
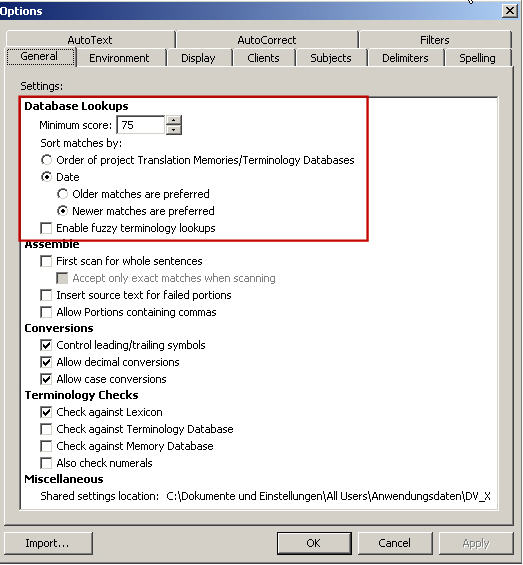
As explained before, for every TM created you have the option to define the threshold at which you want the database to interact with your translation project. This threshold is expressed in terms of exactness or fuzziness, i.e. the degree of similarity of a database segment to the segment to be translated.
Similar and exact matches
Source language segments are automatically matched with equivalent segments in the target language. These equivalent segments in the target language come from previously translated texts. The matches can be similar or exact.
Options
In the graphic on the right you see a window where you can define the minimum score, or degree of fuzziness in percentage terms, that the matches must have in order to be proposed for use. The default setting is 75%, but you can modify it depending on your preferences and the quality and extent of your TM. For example, if you have a very extensive TM you may prefer a higher fuzziness setting, so that only the very similar segments are proposed or used. If you have a relatively small TM you may want to set the fuzziness lower than 75% in order to benefit as much as possible from your TM.