
Erstellen eines Translation-Memory (1/6)
Falls kein TM für die Übersetzung zur Verfügung steht, müssen Sie eines erstellen. Für die TM-Erstellung gibt es zwei Strategien: entweder durch das Übersetzen (das ist die üblichere Methode) oder durch Alignieren früherer Übersetzungen. In beiden Fällen erstellen Sie ein leeres TM, das entweder während des Übersetzungsvorgangs (erstes Szenario) oder mit den Ergebnissen des vorherigen Alignments gefüllt wird.
Ein TM kann auch beim Einrichten eines Übersetzungsprojekts erstellt werden (siehe Kurs TM 4 - Übersetzen mit einem TM) oder jederzeit bevor man mit der eigentlichen Übersetzung beginnt. In letzterem Fall wird das TM als eigenständige Datei erstellt, das später zu jedem Übersetzungsprojekt hinzugefügt werden kann.
Die erste Übersetzung, bei der mit einem TM gearbeitet wird, wird normalerweise mit einem leeren Translation Memory erstellt. Im aktuellen Kurs werden wir ein eigenständiges TM erstellen.
Optionen
Spezielle Optionen für die Definition von Datenbankeinstellungen bei der TM-Erstellung variieren von TM-System zu TM-System, z.B., unterschiedliche Filtertypen, Sprachoptionen. Die für die TM-Erstellung notwendigen Schritte sind bei allen TM-Systemen mehr oder weniger gleich und können wie folgt zusammengefasst werden:
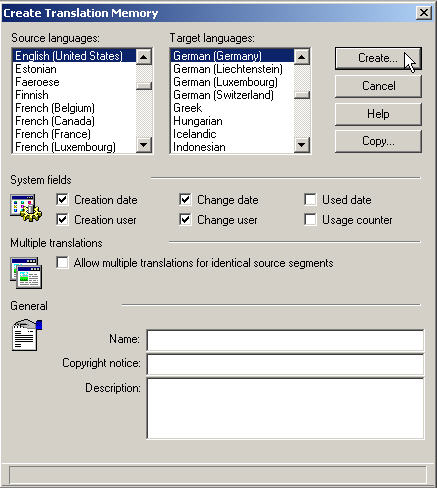
Einer der ersten Schritte bei der Erstellung eines Translation Memories besteht darin, die Sprachen der Daten, die in dem TM gespeichert werden sollen, auszuwählen. Ein TM enthält mindestens zwei Sprachen: die Ausgangssprache und die Zielsprache.
Ein Großteil der TM-Systeme unterstützt alle Sprachen und bei fast allen kann man regionale Varianten festlegen. Bei der Auswahl der Sprachen Ihres TMs ist es wichtig sicherzustellen, dass Sie diese konsequent verwenden, da eine falsche Sprachauswahl oder Sprachvariantenauswahl später zu Problemen führen kann.
Es gibt auch Systeme, wo die Spracheinstellungen vordefiniert und immer alle Sprachen enthalten sind. Wird ein solches System (z.B. DéjàVu X) verwendet, ist es nicht notwendig, die Sprachen zu definieren.
Der Screenshot zeigt die Auswahl der Sprachen bei der Erstellung eines TMs in Trados.

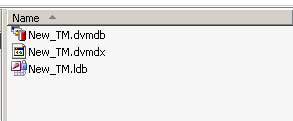
Ein weiterer wichtiger Schritt bei der Erstellung von TMs ist das Dateimanagement. Ein TM besteht aus einer Datei - z.B. einer .txt-Datei in Wordfast - oder aus verschiedenen Dateien in unterschiedlichen Formaten, z.B in DéjàVu X: *.dvmdb, *.dvmdx (diese Dateien werden immer erstellt) und so vielen *.XX.dvmdi-Dateien wie es im TM Sprachen gibt.
Bei diesen Dateien steht anstelle von XX der ISO-Code einer bestimmten Sprache. Deswegen ist es wichtig, die Ordner-Struktur oder Arbeitsumgebung vor Erstellung des TMs zu definieren.
Wenn ein einziges TM erstellt wird, wird der Speicherort im allgemeinen am Anfang des Erstellungsprozesses festgelegt.
Dann wird die leere TM-Datei erstellt. Die Grafik rechts zeigt ein Beispiel für eine TM-Datei "New_TM.dvmdb" für DéjàVu X *.mdb ist die Erweiterung für die Translation-Memory-Datenbank.

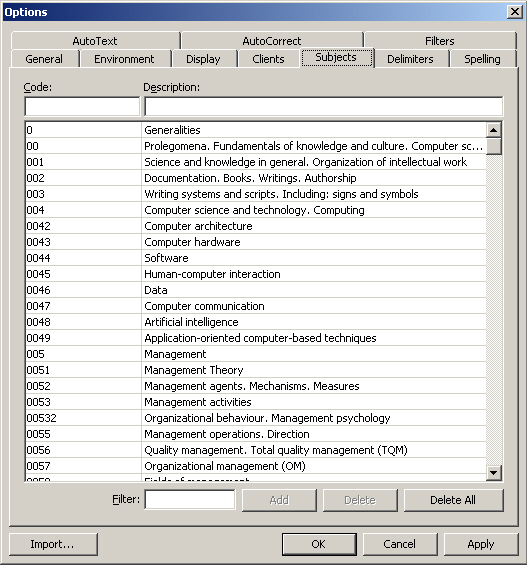
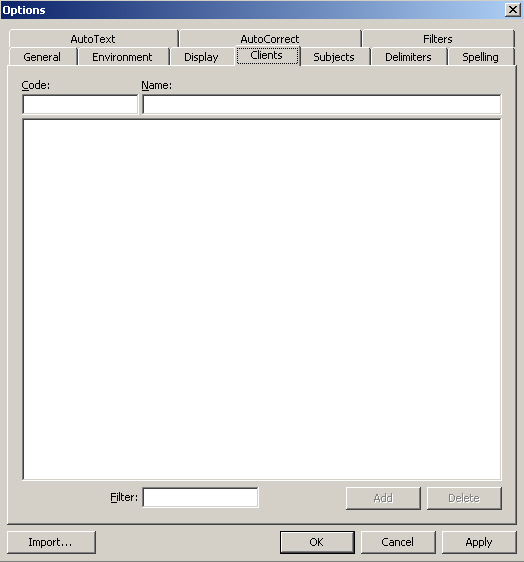
Abhängig vom TM-System gibt es mehrere Optionen von Benutzerdefinitionen, die bei der Erstellung eines TM festgelegt werden können. Benutzerdefinitionen beziehen sich meistens auf Zusatzinformationen zur Datenbank selbst oder zu den Übersetzungseinheiten, die mit Ausgangs- und Zielsegment in der Datenbank gespeichert werden.
Diese Zusatzinformation kann auch als Kriterium für die Extraktion von Daten aus der Datenbank (Filterkriterium) dienen. Es ist zu beachten, dass bei einigen TM-Systemen die Informationsfelder vordefiniert sind. Diese können jedoch je nach den Bedürfnissen der Nutzer bei der Erstellung eines Übersetzungsprojektes (z.B. Déjà Vu) abgeändert werden.
Bei anderen TM-Systemen werden alle Informationsfelder für Benutzerdefinitionen bei der Erstellung einer Übersetzungsdatenbank erstellt und definiert (z.B. Trados).
Beispiele
Benutzer: Name oder Kürzel des Benutzers, der einen bestimmten Eintrag im TM erstellt hat
Datum/Uhrzeit der Erstellung: Datum und Uhrzeit der Eingabe des Eintrags in die Datenbank
Fachgebiet: Fachgebiet oder Spezialgebiet der in der Datenbank enthaltenen Texte
Kunde: Vom Benutzer zugewiesener Kunde in einem Datensatz
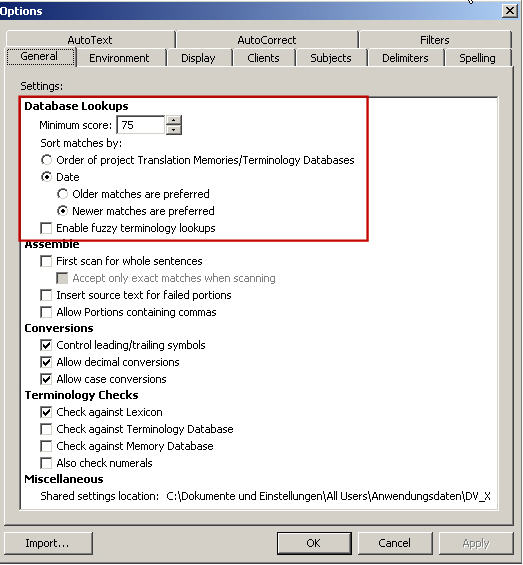
Wie zuvor dargelegt, hat man für jedes erstellte TM die Möglichkeit, den Schwellenwert zu definieren, der bei einem Übersetzungsprojekt greifen soll. Dieser Schwellenwert wird als exaktes Match oder Fuzzy Match-Wert dargestellt, d.h. der Grad der Übereinstimmung eines Datenbanksegments im Vergleich zu dem zu übersetzenden Segment wird angezeigt.
Exakte und Fuzzy Matches
Ausgangssprachliche Segmente werden automatisch zielsprachlichen Segmenten zugeordnet. Die entsprechenden zielsprachlichen Segmente stammen aus früheren Übersetzungen. Die Treffer können exakte Treffer oder Fuzzy Matches sein.
Optionen
Im Screenshot sehen Sie ein Fenster, in dem man den kleinstmöglichen Übereinstimmungsgrad, den die für die Übersetzung vorgeschlagenen Treffer haben müssen, in Prozent festlegen kann. Der vorgegebene Wert beträgt 75%, doch Sie können diesen je nach Qualität und Größe ihres TMs modifizieren.
Wenn Sie zum Beispiel ein sehr großes TM haben, ziehen Sie vielleicht einen höheren Übereinstimmungsgrad vor, so dass nur sehr ähnliche Segmente vorgeschlagen werden. Wenn Sie ein relativ kleines TM haben, möchten Sie vielleicht lieber einen niedrigeren Übereinstimmungsgrad als 75% haben, um das TM so gut wie möglich nutzen zu können.