
Solution
La capacité de Word à ouvrir et sauvegarder des fichiers en texte brut dans un grand nombre d'encodages différents vous permet de convertir un fichier dont les caractères sont codés d'une certaine manière en un fichier utilisant un encodage différent. Cela permet également de savoir quel système d'encodage a été utilisé pour encoder une partie du texte.
Cela peut être très utile lorsque vous travaillez avec des informations glanées sur l'Internet où des systèmes plus anciens prévalent. Cela permet également de convertir des fichiers qui ont été créés avec des applications qui ne sont pas Unicode. En convertissant de tels fichiers en Unicode vous augmentez le nombre d'applications susceptibles de traiter les données contenues.
Pour convertir des encodage de caractères:
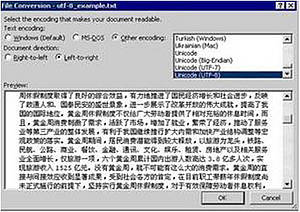
Ouvrir le fichier dans Word en sélectionnant Ouvrir dans le menu Fichier. Word va certainement identifier correctement l'encodage utilisé
Si vous êtes certain qu'un codage différent a été utilisé pour le fichier que vous voulez ouvrir, vous pouvez ignorer la suggestion de Word en utilisant la fenêtre de dialogue Conversion de fichier qui s'ouvre automatiquement
Une fois le fichier ouvert avec succès, l'enregistrer en texte brut comme expliqué dans la question 19. S'assurer d'avoir sélectionné l'encodage dans lequel vous souhaitez convertir votre donnée.
Pourquoi cette information est-elle importante pour les traducteurs et les professeurs de traduction ?
Puisque l'encodage de caractères dépend de la langue (différentes langues utilisent différents caractères, il existe différents alphabets ainsi que des lectures horizontales, verticales, de gauche à droite ou de droite à gauche) et que les langues constituent l'essence même du travail de traducteur, les traducteurs doivent non seulement savoir qu'il existe différents types d'encodages de caractères mais également savoir les utiliser.
Lorsqu'ils travaillent avec plusieurs langues en même temps, les traducteurs doivent convertir des encodages de caractères afin de pouvoir visualiser correctement les caractères d'une même page ou d'un même document. L'un des encodages de caractères les plus utilisés en traduction est l'encodage standard Unicode puisqu'il contient toutes les langues. Il est de plus en plus utilisé par les logiciels et permet l'échange de données sans souci de compatibilité.
L'encodage de caractères prend toute son importance pour la traduction de site Web ou la localisation en général.